|
I am a Principal Applied Scientist in Amazon AGI. I closely collaborate with AWS AI Labs. Before this, I was an applied scientist in Amazon Halo where I worked on problems at the intersection of Computer Vision and Health. Prior to Amazon, I was a Principal Computer Vision Researcher at Magic Leap. I finished my Ph.D. from the School of Interactive Computing at Georgia Institute of Technology. I was advised by Professor Henrik I. Christensen and Professor Frank Dellaert. I completed my Bachelors and Masters in Computer Science from IIIT Hyderabad where I was advised by Prof. P J Narayanan. |

|
The Multimodal Mind
The next frontier in AI is a single model that understands the physical world well enough to imagine its futures and act to shape them — a natively multimodal foundation model that perceives, reasons, and generates across all modalities (image, video, text, speech, action), organized around a three-stage cognitive loop: Perceive → Imagine → Act. Perceive ingests the current state across modalities in a unified space. Imagine thinks in multimodal space — mental video of the planned trajectory, predicted proprioception, anticipated contact forces — and this imagination is the world model. Act generates whatever output the task requires (motor commands, keyboard/mouse, speech), conditioned on the imagined plan. Under this view, controllable video generation, computer use, robotics, world simulation, autonomous driving, and creative tools are all different routes through the same architecture — and improvements to the shared backbone benefit every task simultaneously. [full writeup]

|
AWS re:Invent, 2025 (Tech-lead on multimodal pre-training team) Technical Report
Tech-lead for Nova 2.0 Lite: Core-team member focused on designing MM architecture and finalized pretraining data mix and recipe integrating vision, speech and language understanding at scale. Achieves state-of-the-art performance on 13 out of 15 benchmarks vs Claude Haiku 4.5.
|
|
|
AWS re:Invent, 2024 (Tech-lead on multimodal pre-training team) Technical Report Tech-lead on multimodal pre-training team responsible for developing image/video pretraining recipes for Amazon Nova foundation models. Achieved state-of-the-art performance on multimodal understanding benchmarks against Claude 3 Haiku and Gemini 1.5 Pro. The family includes Nova Pro, Nova Lite, Nova Micro, Nova Canvas, and Nova Reel. Media Coverage: TechCrunch / AWS Insider / Business Wire / Technology Magazine / About Amazon |
|
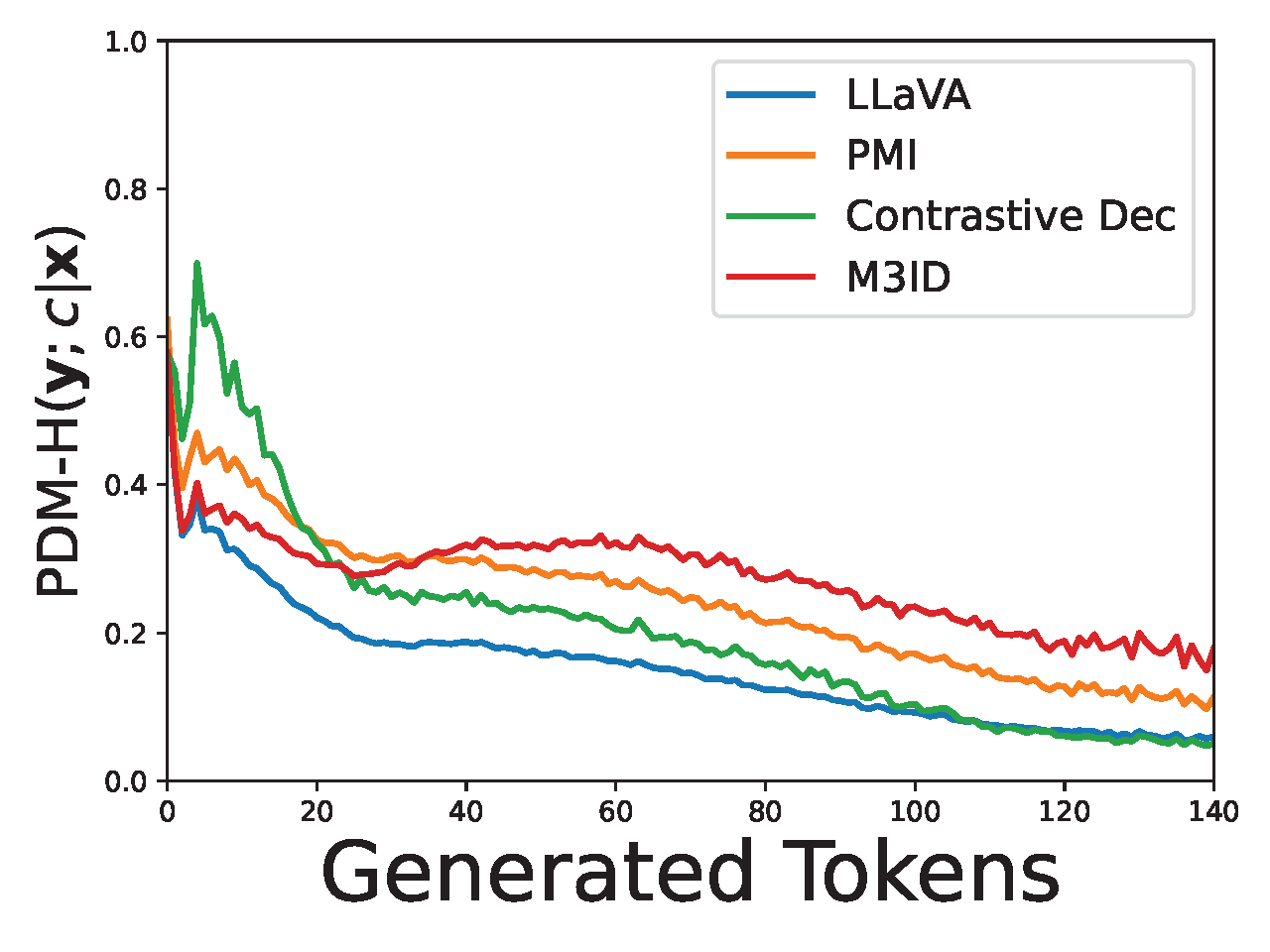
Alessandro Favero, Luca Zancato, Matthew Trager, Siddharth Choudhary, Pramuditha Perera, Alessandro Achille, Ashwin Swaminathan, Stefano Soatto, CVPR, 2024 arXiv / web We address hallucination in Generative Vision-Language Models by introducing Multi-Modal Mutual-Information Decoding (M3ID), which amplifies the influence of reference images, reducing hallucinated responses by up to 28% without compromising linguistic fluency. |

|
Varun Nagaraj Rao, Siddharth Choudhary, Aditya Deshpande, Ravi Kumar Satzoda, Srikar Appalaraju, arXiv, 2024 arXiv / web RAVEN is a multi-task retrieval-augmented vision-language model framework that improves performance on various tasks through efficient fine-tuning without requiring additional parameters. |
|
3D Human Reconstruction and Health CVML |
|
|
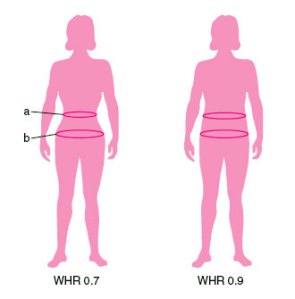
Siddharth Choudhary, Ganesh Iyer, Brandon M. Smith, Jinjin Li, Mark Sippel, Antonio Criminisi, Steven B Heymsfield Nature Digital Medicine, 2023 (Shipped with Amazon Halo Body) pdf / web / citation Propose a CNN based model called MeasureNet for accurately and reliably predicting body measurements and waist-hip ratio. Model is trained using realistic synthetic dataset. Media Coverage: Fierce Biotech / About Amazon / Amazon Science |
|
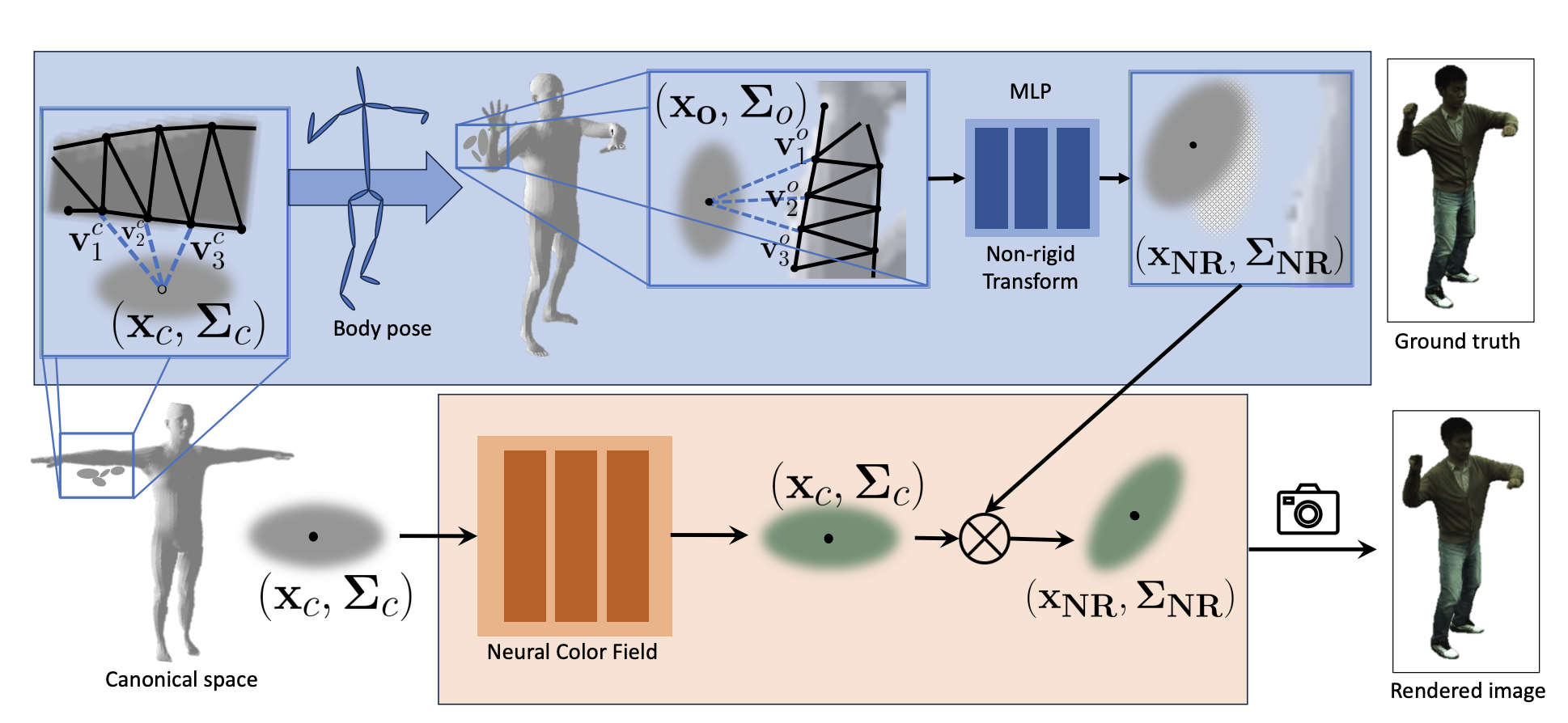
Rohit Jena, Ganesh Iyer, Siddharth Choudhary, Brandon M. Smith, Pratik Chaudhari, James C. Gee, arXiv, 2023 arXiv / web A fully articulated Gaussian splatting model for human avatars. Our model includes both rigid and non-rigid skinning components, and a Neural Color Field for implicit color regularization. |
|
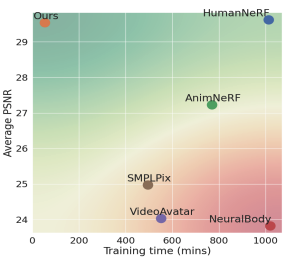
Rohit Jena, Pratik Chaudhari, James C. Gee, Ganesh Iyer, Siddharth Choudhary, Brandon M. Smith arXiv, 2023 arXiv Optimizing a SMPL+D mesh and an efficient, multi-resolution texture representation for novel view synthesis and pose synthesis. |

|
Siddharth Choudhary, Brandon M. Smith, Jinjin Li, Yaar Harari, Abhishek Dubey Amazon Computer Vision Conference, 2023 (Best Paper Award) PDF (on request) A two-stage transformer-based system analyzes real-time fitness videos using pose sequences to detect exercise repetitions, classify movements, and identify form errors with severity levels. |
|
Augmented Reality |
|

|
Siddharth Choudhary, Nitesh Sekhar, Siddharth Mahendran Prateek Singhal CVPR Workshop on AR/VR, 2020 (Shipped on Magic Leap One) pdf / project page / bibtex An approach for multiuser and scalable 3D object detection, based on distributed data association and fusion. |
|
Distributed Object SLAM |
|
|
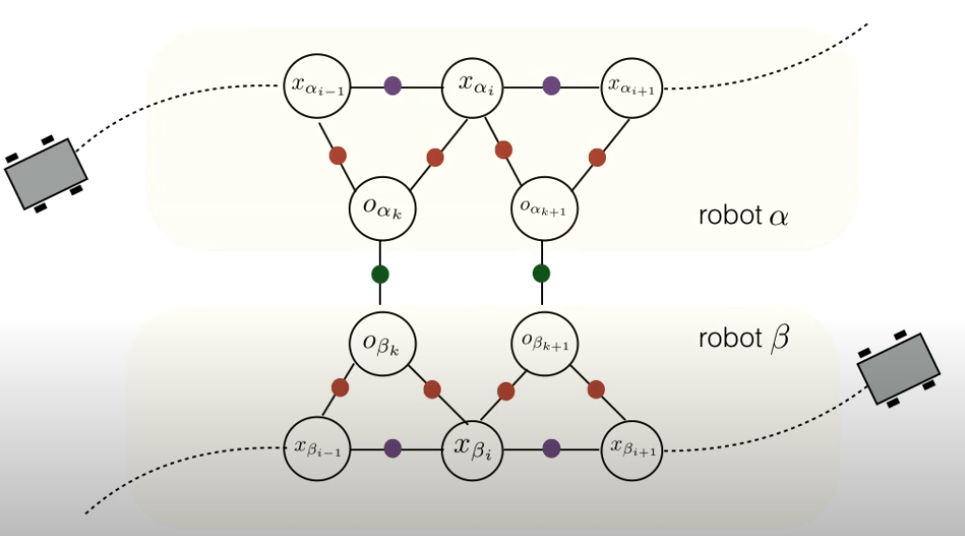
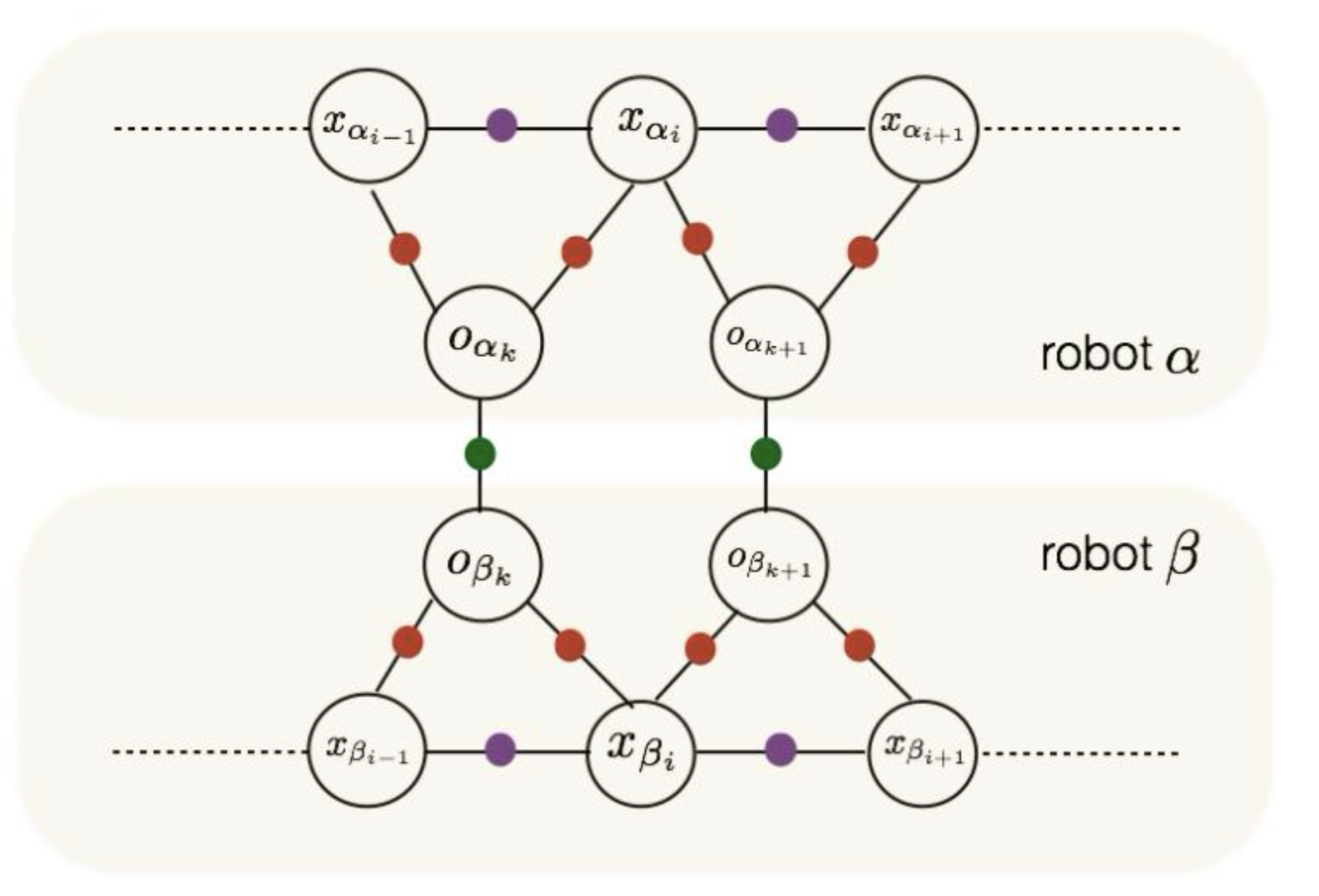
Titus Cieslewski, Siddharth Choudhary, Davide Scaramuzza ICRA, 2018 pdf / video / code / bibtex Decentralized visual SLAM combining distributed PGO using Gauss-Seidel and efficient, distributed place recognition using NetVLAD features. |
|
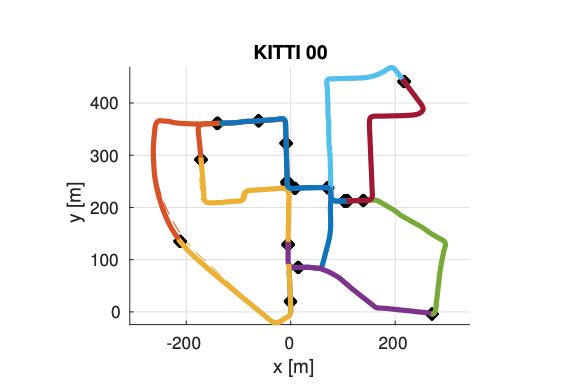
Siddharth Choudhary PhD Thesis, 2017 pdf / ppt Decentralized object based SLAM combining distributed PGO with joint modeling and mapping of object landmarks. Media Coverage: The Economist |
|
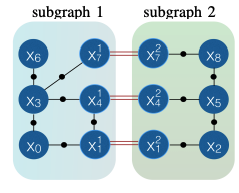
Siddharth Choudhary, Luca Carlone, Carlos Nieto, John Rogers, Henrik I. Christensen, Frank Dellaert IJRR, 2017 arxiv / code / video / bibtex Propose a distributed implementation of the two-stage pose graph optimization, using Successive Over-Relaxation (SOR) and the Jacobi Over-Relaxation (JOR) as workhorses to split the computation among the robots. Extends it to work with object-based map models. |
|
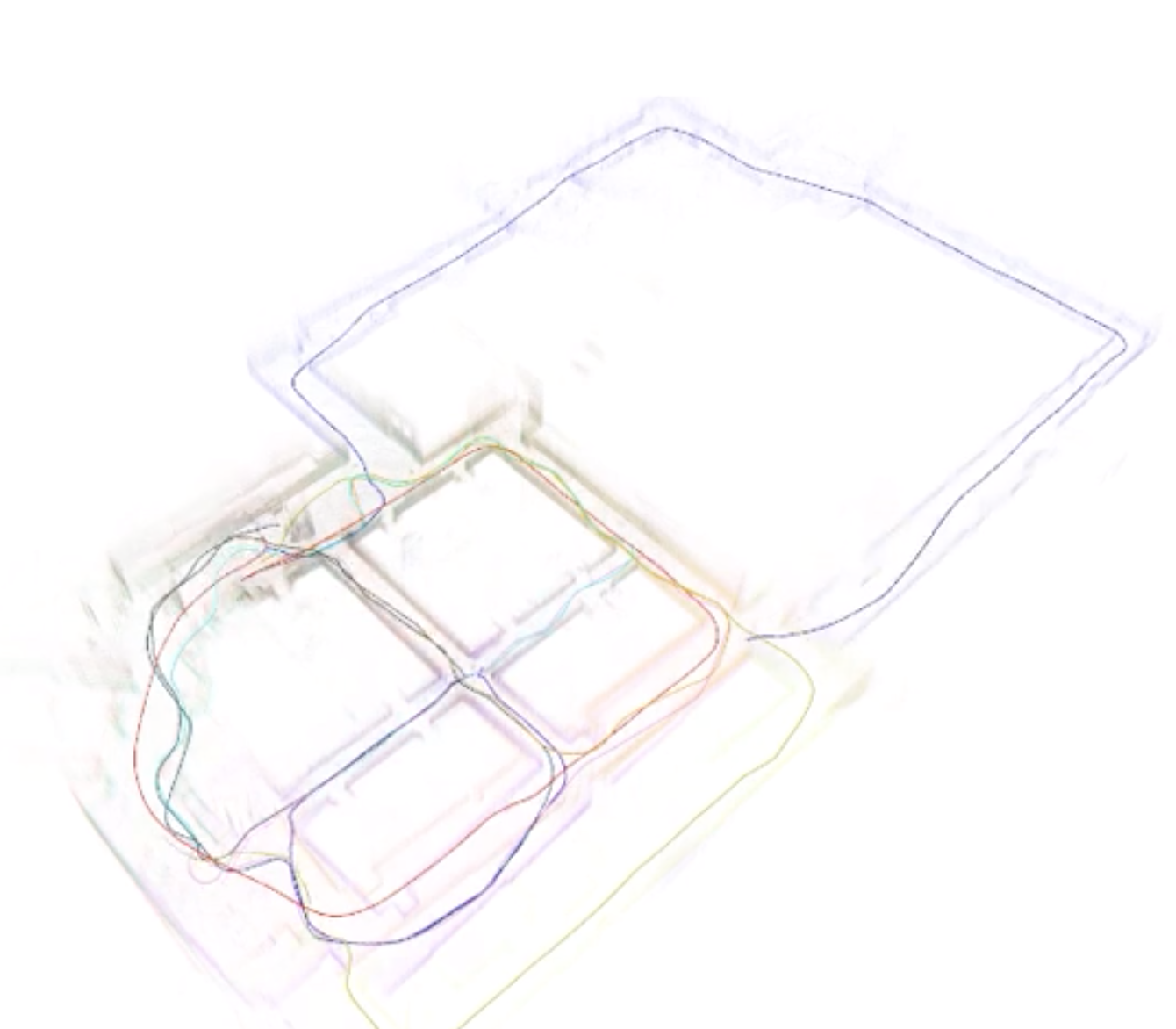
Siddharth Choudhary, Luca Carlone, Carlos Nieto, John Rogers, Zhen Liu, Henrik I. Christensen, Frank Dellaert ISER, 2016 pdf bibtex Multi robot SLAM approach that uses 3D objects as landmarks for localization and mapping. Leverages local computation at each robot (e.g., object detection and object pose estimation) to reduce the communication burden. |
|
Siddharth Choudhary, Luca Carlone, Carlos Nieto, John Rogers, Henrik I. Christensen, Frank Dellaert ICRA, 2016 pdf / ppt / www / video / bibtex Leverages recent results which show that the maximum likelihood trajectory is well approximated by a sequence of two quadratic subproblems and solves it in a distributed manner, using the distributed Gauss-Seidel (DGS) algorithm. |
|
Varun Murali, Carlos Nieto, Siddharth Choudhary, Henrik I. Christensen IROS, 2016 pdf / code Plans a trajectory which actively reduces the uncertainty of the robot's calibration given a rough initial calibration estimate. |
|
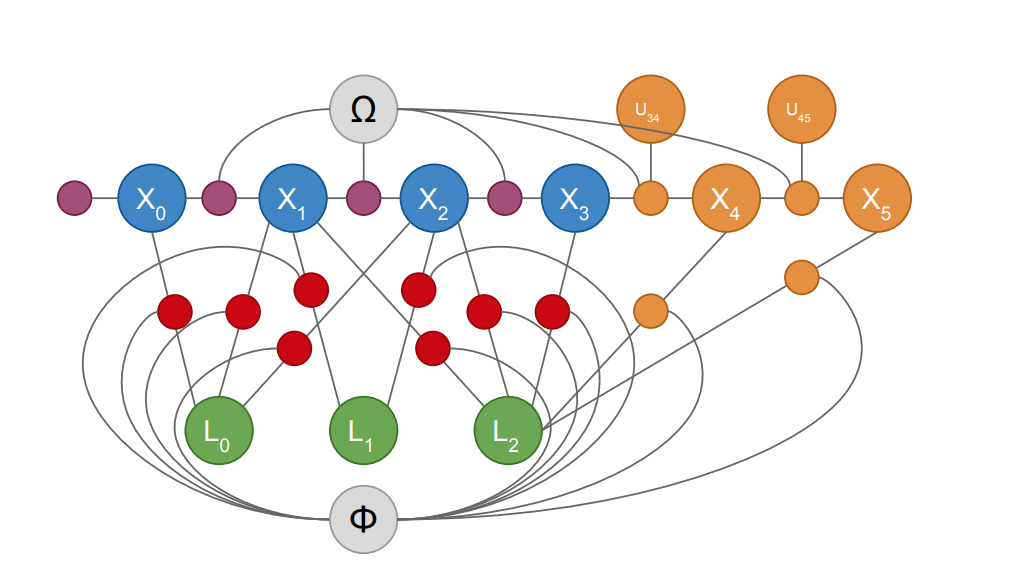
Siddharth Choudhary, Luca Carlone, Henrik I. Christensen, Frank Dellaert IROS, 2015 pdf / code / bibtex Scalable SLAM using multiblock Alternating Direction Method of Multipliers (ADMM). |
|
Siddharth Choudhary, Vadim Indelman, Henrik I. Christensen, Frank Dellaert ICRA, 2015 pdf / bibtex Information theoretic algorithm to efficiently reduce the number of landmarks and poses in a SLAM estimate without compromising the accuracy of the estimated trajectory. |

|
Siddharth Choudhary, Alexander J. B. Trevor, Henrik I. Christensen, Frank Dellaert IROS, 2014 pdf / bibtex Propose an approach for online object discovery and object modeling, and extend a SLAM system to utilize these discovered and modeled objects as landmarks to help localize the robot in an online manner. |
|
Structure from Motion / GPU Computing |
|
|
Kishore Kothapalli, Dip Sankar Banerjee, P. J. Narayanan, Surinder Sood, Aman Kumar Bahl, Shashank Sharma, Shrenik Lad, Krishna Kumar Singh, Kiran Matam, Sivaramakrishna Bharadwaj, Rohit Nigam, Parikshit Sakurikar, Aditya Deshpande, Ishan Misra, Siddharth Choudhary, Shubham Gupta arXiv, 2013 arXiv |
|
Aditya Deshpande, Siddharth Choudhary, PJ Narayanan, Krishna Kumar Singh, Kaustav Kundu, Aditya Singh, Apurva Kumar ICVGIP, 2012 pdf / bibtex |
|
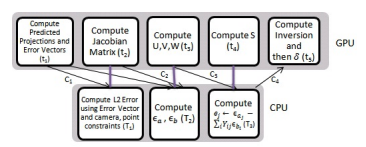
Siddharth Choudhary MS Thesis, 2012 pdf / www |
|
|
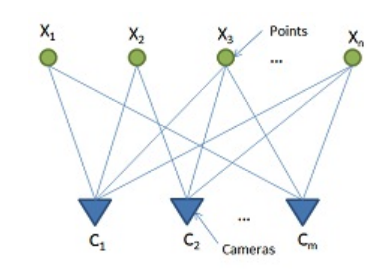
Siddharth Choudhary, P. J. Narayanan ECCV, 2012 pdf / www / bibtex Encode the visibility information between and among points and cameras as visibility probabilities for improved localization and triangulation. |
|
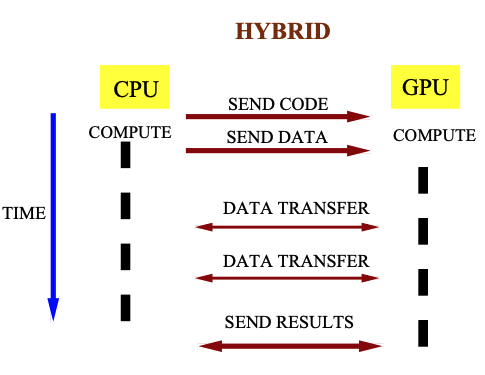
Siddharth Choudhary, Shubham Gupta, P. J. Narayanan ECCV CVGPU Workshop, 2010 pdf / ppt / tutorial Hybrid implementation of sparse bundle adjustment on the GPU using CUDA, with the CPU working in parallel. |
- 2026 LLM Sandbox Train small language models in the browser with real-time visualization.
- 2026 Physical Therapy Exercise Programs Interactive anatomy-based PT exercise programs.
- 2026 ML Coding Lab LeetCode-style practice problems for ML interviews.
- 2026 The Optimizer Ladder: From SGD to MuonH A guided tour through neural-network optimizers with twelve interactive widgets.
- 2026 Speech-to-Speech Models: A Literature Review Comprehensive review of end-to-end speech models from SpeechGPT (2023) to Qwen3-Omni (2025).
- 2019 Literature Review on Minimal Mapping for Navigation
- 2019 SLAM Literature Review
- 2019 Bundle Adjustment Tutorial